先猜一道题:总听专家们说“拐点”“拐点”,但哪个才算拐点呢?
数学定义上的拐点 inflection point,可能要让朋友们失望了:

如果就拐点处红色箭头的角度做个镜像,就纵轴的上涨幅度而言,拐不拐,也许对传染病专家的建模有些不同的含义,但对普通民众来说,它又有什么关系呢?同样会经历一个纵轴的快速攀升,和之后虽稍缓但仍旧保持爬坡的状态。就在Y轴上的增长幅度看,与从X轴起势的阶段也没有太大区别。若以爬山来举例,“拐点”有点儿像是在半山腰喘口气,然后接着爬……
三、多国疫情图的形态
平时读专业文章时,我也是一鼓作气、再而衰、三而竭,读完立即就昏睡了,就像当机了。所以我写的时候,尽量来写成好理解的~~
前篇说过,可以将半对数图近似看作“加速度”,为什么说“近似”呢?因为lg=log 10的作用是降指数。能降多少层级指数呢?可以说有多少降多少:比如1亿是10的8次方,lg完就剩下常数8了,好比一只花枝招展的孔雀正转着圈伸展着颤动的翎毛,lg一下就褪了毛了,啥都不剩只留下光秃秃一只肉鸡。加速度只是比速度浓缩一个级别,相当于求导dt,而lg能还原掉所有的指数级,作用更厉害呢~~
咱们来猜个谜,下面这些国家的图形有哪些相近,又有哪些不同呢?
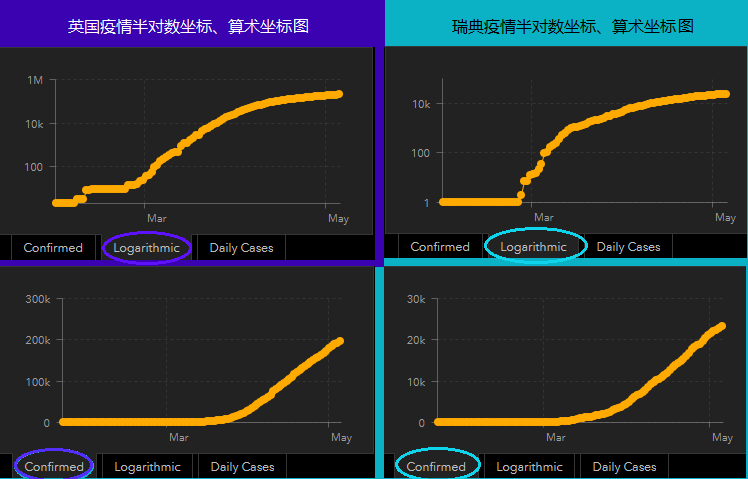
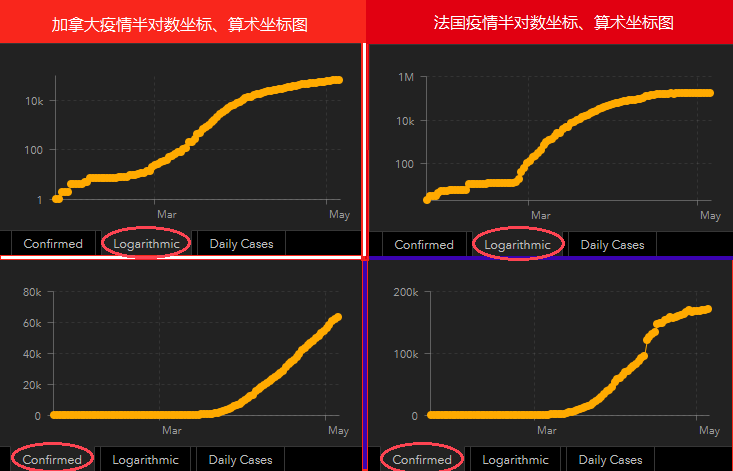
我们会略有些吃惊地看到,最令人瞩目的两个国家,英国和瑞典,都斯巴达勇士般在推广“群体免疫”的概念,它们的图与医疗资源遭受挤兑的意大利,与感染人数最多的美国,与紧跟其后的法国、加拿大的图形其实没有太大的差别。

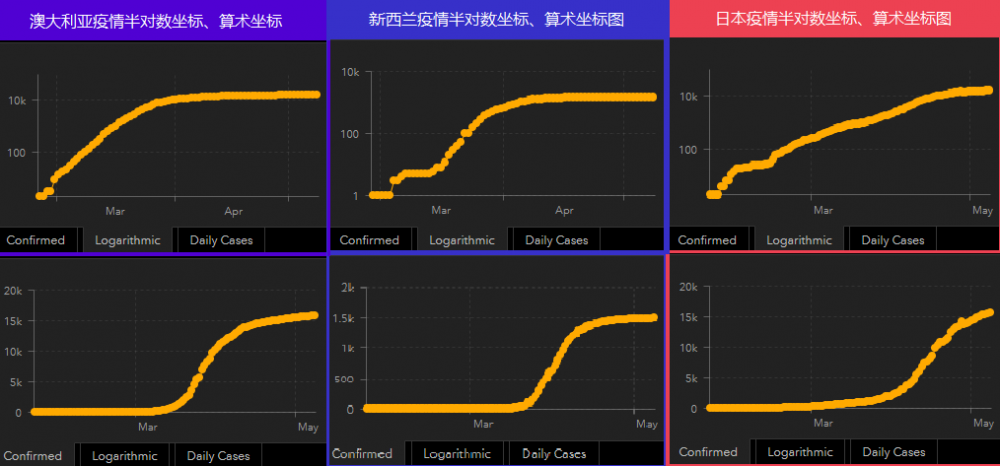
上图可见,三个岛国中,澳大利亚和新西兰图形也是非常像。日本与它们不同,算是很顽强的了,疫情一开始就参与其中,一直维系着较慢的升幅,眼看着不少国家纷纷超过了它(当然也有其他的一些原因,后面会谈到)。
怎么上下图结合着看呢?可以近似理解为:
- 半对数图(上图)冲得快时,算术坐标图(下图)会像下弦月一样朝天翘 上去了。
- 当半对数图(上图)爬坡缓慢趋于平缓时,算术坐标图(下图)的增长沿着原先的趋势,速度会越来越快,但至少没原先冲的那么厉害。
- 当半对数图(上图)向右上趋缓渐平,算术坐标图(下图)接近于匀速上升。
数学是个工具,用来帮助我们理解事物的主要结构,可多用近似的方法来推测,别被那些具体的术语把思路限定在了细微处。
四、多国疫情图,一次二次的简单形态
从这些图的算术坐标图(下图)看,它们或者是直线,或者是“曲线+部分段落的直线”。
很多科学家正就新冠感染总人数建模,只是这种形态的建模不是有些太简单了吗?若沿用近似的演绎方法,一次线性 + 二次曲线,看似就可以模拟了。
建模中,计算量大些的是“回归”的计算,就是动态地根据趋势的每步进展(根据最新发生的真实数据)来一天天地调整对未来趋势的预测。特别是“多元回归”,简单地说就是假设了多个可变量,X、Y、Z,还有H、J那些,各个假设量都在变……但按目前这样形态的疫情图,回归计算也就没什么必要了,线性+弧形曲线就足够了,即使退而求其次,打个简单的区间段出来,也足够实现预测功能了。杀鸡焉用牛刀,哪里还用得上“回归”呢?
五、多国疫情图被线性因素限制住了——“新冠检测量”
多国疫情图为何如此相似呢?推测其中的原因,我觉得是在疫情的发展中,一些线性因素在主导着感染总人数的曲线,比如“新冠检测量”成为了瓶颈因素,使得“事实感染总人数”所应呈现的指数增长那种一飞冲天的形态不能被显现、无法被计数,于是新冠疫情图上的所谓的感染总人数曲线,因为瓶颈的存在,事实上已悄然被"累计总检测人数”、以及“总检测人数中的感染密度”这两个概念的复合效果所替代。
形象一点儿,想象我们正处于一片广阔的大陆上,这里的人数多乎其多,我们正在寻找人群中有某类特点的人。但由于我们只能以步行的速度去探索这块未知的大陆地,所以在纸上所能记下的,都受限于我们步履所能达到的有限区域,与真实数字之间会存在一个差异缺口......(至于这个缺口到底有多大?这是又一个数学题了,等写完主要的结构,若还有时间也还有必要,那我们再来推一推)......
于是,当每日的新冠检测量还受限于线性或有限幅度的增长,当然是无法追上真实感染总人数那种云在天上的指数增长形态了,各国疫情图于是就成了现在这种简单趋同的形态了。
如果这一推论正确,按说逆否命题也会同样正确,而令人更好奇的是它的逆命题可否成立?也就是说当某些国家的COVID-19确诊总人数的算术坐标图(下图)如果呈现了简单的“线性+二次曲线”形状时,我们可否断定它的检测量/确诊方式一定数量不足,已成为了瓶颈因素而无法真正显现指数级的感染趋势?
下篇更精彩,未完待续~~
以往文章:
(1)新冠疫情图的数字奥秘
https://blog.wenxuecity.com/myoverview/67349/
相当乐观的魁省“悲观预测”
https://blog.wenxuecity.com/myblog/67349/202004/20157.html
交叉感染之源,Montreal市中心COVID-19检测点的选址问题
https://blog.wenxuecity.com/myblog/67349/202004/4468.html
Montreal女市长的神操作—新冠病毒检测点设在了市中心
https://blog.wenxuecity.com/myblog/67349/202003/40265.html