生成式人工智能的出现,将人类带入一个机器生成内容与人类原创内容深度交织的世界。
以 Sora、Midjourney为代表的AIGC模型,展示了人类通向通用人工智能(AGI)的想象力,也让虚假影像以前所未有的速度涌入公共空间。而人类的识别速度却远远落后于造假的节奏。
在此背景下,“以AI辨AI”似乎成为一种可行的思路:人工智能如何定义“真实”的边界?大模型能否辅助核查员和读者完成核查工作?
为此,“澎湃明查”发起挑战,将ChatGPT、Gemini、DeepSeek、豆包等热门模型请上了实验台。
背景
2024年2月,一段由 Sora 生成的“樱花雪景”视频在网络上引发热议。视频中樱花飘落的细节可谓逼真,却被谷歌的智能模型 Gemini 1.5瞬间识破为AI作品。
这个案例带来了启示:我们或许可以依靠AI本身来识别AI视频。
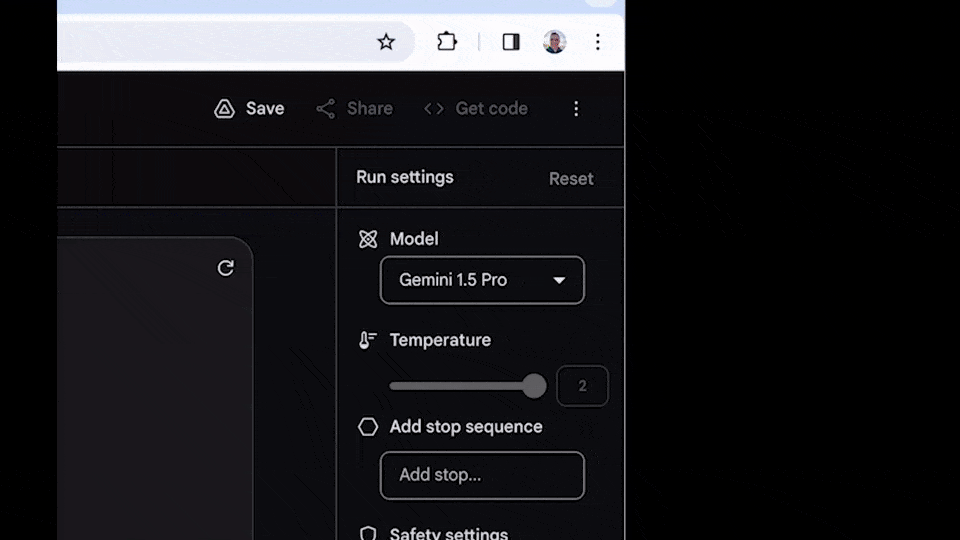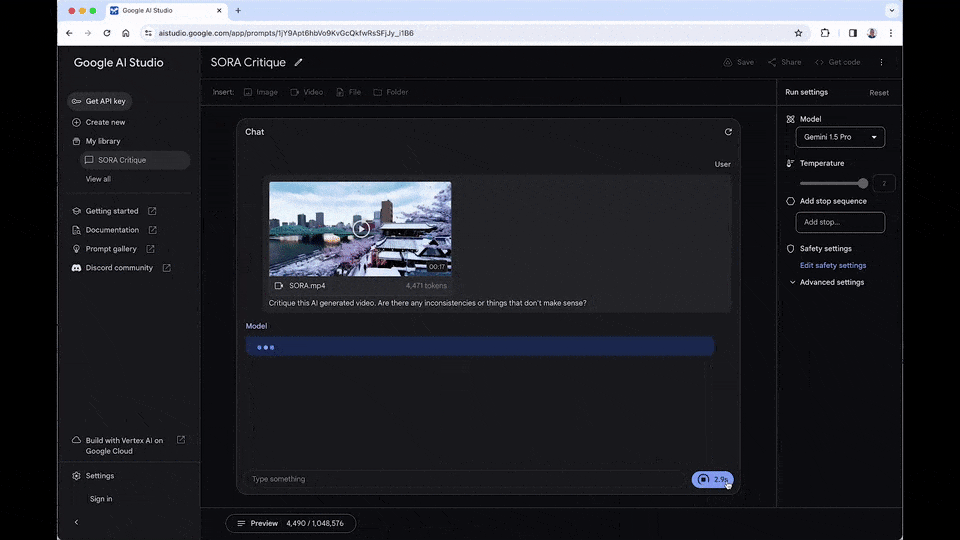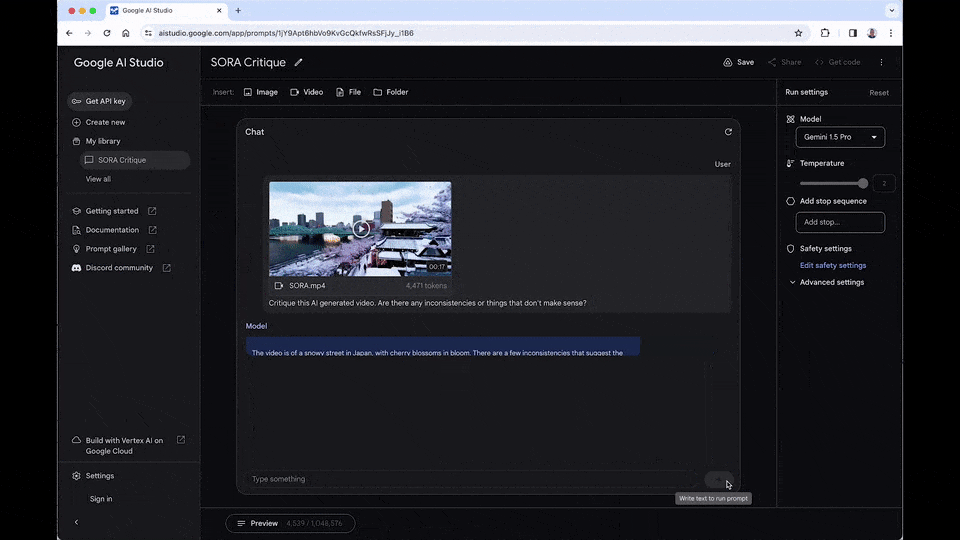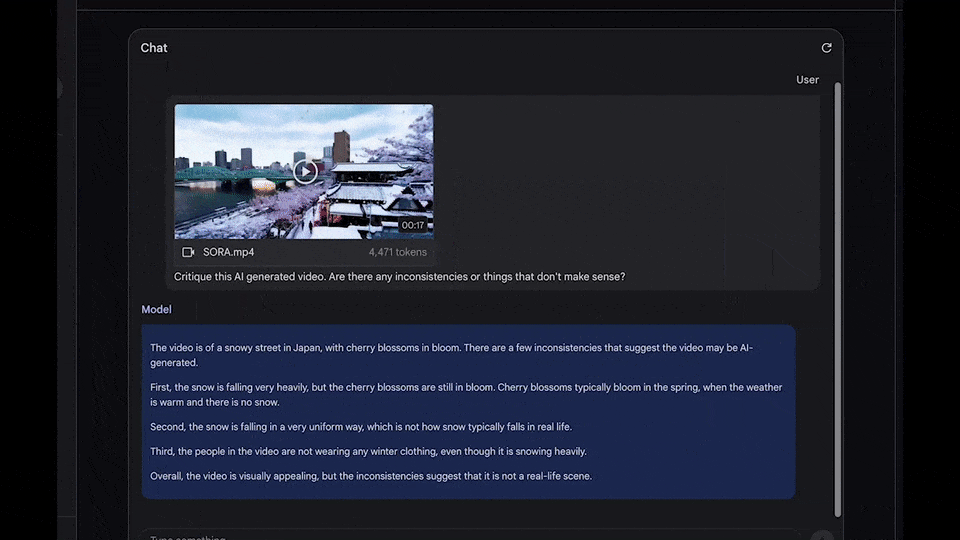
基于这一思路,我们尝试搜寻能够直接读取视频文件的大语言模型。但现阶段,面向公众开放且具备视频解析能力的商业模型仍十分有限——包括国产大模型“豆包”、马斯克团队研发的Grok在内的众多大语言模型都暂未支持视频检测或网页端上传视频功能。经过筛选,我们最终选择了 Gemini 2.5 Pro 和 ChatGPT-5 进行测试。
我们为两款模型各准备了12段视频:其中3段由不同的文生视频模型生成,3段含有深伪(deepfake)元素,3段使用计算机生成图像(CGI),另有3段为真实拍摄素材。针对每段视频,我们向模型提出相同的问题:这段视频是真实拍摄的,还是经过后期制作的?它所展示的内容是否与网传说法一致?
借此提问,我们不仅想探究大模型的识假、辨假能力,更想了解,大模型在划定“真实”与“虚构”的边界时,会采用何种视角与逻辑。
明查
真实与虚构的界线
在事实核查中,一段真实的视频,往往意味着它是对我们所处的物理世界的实景记录。而凡是经由计算机技术生成的影像,即便包含高度拟真乃至还原现实的元素,本质上仍属于虚构。
在这一点上,大模型与核查员的认知是一致的。当我们将一段“游戏模拟俄战机着陆航母”的画面投喂给ChatGpt时,模型会告诉我们“该视频为电脑生成影像(CGI)或后期合成制作的影像,不属于真实世界实景拍摄”。而在识别“2024年1月日本石川县能登半岛地震画面”时,模型则表示,“该视频属于真实拍摄。没有发现AI生成、深度伪造或重大后期合成制作的迹象。”
在测试中,仅就“是否使用计算机生成图像”这一维度而言,Gemini 2.5 pro的表现令人惊叹。它不仅几乎准确识别了全部12段视频,且对于使用了不同计算机技术,如AIGC或CGI的画面,也能进行区分。但在识别深伪视频,如“美国女歌手泰勒·斯威夫特说中文接受访谈”的画面时,Gemini虽能察觉到视频经过编辑,其音频部分有异样,却无法明确指出异常源自深伪技术。

在识别“美国女歌手泰勒·斯威夫特说中文接受访谈”的画面时,Gemini虽能察觉到视频经过编辑,但无法明确指出异常源自深伪技术。
相较之下,ChatGPT 的表现略显逊色,仅对12段视频中的7段作出相对准确的判断,并将所有深伪视频误判为了“真实拍摄的录像”。此外,ChatGPT 在技术辨识上不会着意对AI生成的内容和CGI内容进行区分。在判断一段来自《数字战斗模拟世界》(DCS World)的游戏视频时,ChatGPT多次声称在视频中找到了“AI生成视频”的痕迹。

ChatGPT 在技术辨识上不会着意对AI生成的内容和CGI内容进行区分,且可能错认。
在画面内容理解方面,两款模型各有侧重。ChatGPT倾向于从视频关键帧中寻找与描述相符或矛盾的证据;Gemini则会结合联网搜索结果,对视频主题进行综合判断。
无论是ChatGPT还是Gemini,都存在“AI幻觉”的问题。例如,在辨认一段实际拍摄于中国浙江海宁市的盐官潮乐之城景区的视频时,ChatGPT虽然能够判定视频是真实拍摄的,未经过显著后期合成或生成式处理,却将视频展示的内容确认成了迪拜“Surreal”瀑布现场。Gemini则在不同时间,面对相似的提问,先后做出了视频拍摄于“浙江海宁盐官”和“中国苏州高新区文体中心”的回答,可见该模型的鲁棒性亦存在缺陷。
而ChatGPT在测试中更是多次给出了前后逻辑不一致的回答。例如,在判断“美国总统特朗普与前总统拜登共同度假”的深伪视频检测中,ChatGPT 先称视频为“真实录像”,在变换提问方式后又改口称视频为“经过换脸合成的伪造内容”。


在判断“美国总统特朗普与前总统拜登共同度假”的深伪视频检测中,ChatGPT 先称视频为“真实录像”,在变换提问方式后又改口称视频为“经过换脸合成的伪造内容”。
总体来看,目前能对视频真实性做出系统判断的大模型仍然稀少且存在缺陷。Gemini 在识别计算机生成影像方面表现突出,但在内容理解上仍易受幻觉干扰。值得注意的是,无论是 Gemini 还是 ChatGPT,对真实拍摄的视频均能保持较高识别准确率。这意味着,模型或许会被欺骗,但鲜少会进行“诬陷”。
像AI一样思考
Gemini不完美,但它答对了12道题。它是怎么做到的?
将Gemini与ChatGPT进行横向比较,可以观察到,二者在面对相同的视频真伪判断问题时,采用的分析路径存在巨大差异——如果赋予模型以个性,那么,ChatGPT就像是一位端坐在实验室中的检测人员,动辄提视频分辨率、帧率、总帧数、平均图像锐度、噪声水平和边缘密度等技术名词。而Gemini则像是一名富有经验的侦探,一会儿考察画面本身的细节,一会儿核对视频内容与外部资料能否交叉验证,同时留心技术的传播时间线,评估视频制作的难度。
例如,在对一段由Sora 2制作“日本民众声援日本首相高市早苗”的文生视频进行分析时,ChatGPT根据“图像边缘平滑”“光照和阴影分布呈‘合成光’特征”“帧间连续性过于稳定”“画面缺乏真实传感器噪点结构”等技术维度,得出了视频“经过后期合成或AI生成制作”的结论。而Gemini则从视频中清晰可见的水印(并搜索了解了该水印的含义)、画面上乱码的文字和人物轻微扭动的非自然细节中“看”出了视频“完全是由AI生成的”。

ChatGPT-5根据“图像边缘平滑”“光照和阴影分布呈‘合成光’特征”“帧间连续性过于稳定”“画面缺乏真实传感器噪点结构”等技术维度,得出了视频“经过后期合成或AI生成制作”的结论。

Gemini从视频中清晰可见的水印、画面上乱码的文字和人物轻微扭动的非自然细节中“看”出了视频“完全是由AI生成的”。
在辨认另一段展示了“伊朗海边鲇鱼被海浪冲上海岸后死亡”的真实视频时,ChatGPT从光影一致性、运动连续性、纹理与噪点分布、边缘检测与色彩统计和音视频同步出发,做出了判断。而Gemini则考虑了视频画面的一致性、动态连续性、时间真实性与视频的制作难度。
诚然,ChatGPT的技术分析路径有其优势,能够发现人们使用肉眼难以察觉的异常细节。例如,在识别上述“美国女歌手泰勒·斯威夫特说中文接受访谈”的深伪视频时,ChatGPT能够通过声纹分析和人物面部出现异常的块状伪影等技术特征,判断出该视频为深度伪造内容。而Gemini认为视频中出现的音画不同步只是在真实的视频片段上增加了配音,判断并不精准。

ChatGPT能够通过声纹分析和人物面部出现异常的块状伪影等技术特征,判断出该视频为深度伪造内容。
但ChatGPT的分析方式在日常生活中难以被普通人借鉴。在没有背景知识的加持下,模型罗列的专有名词,也可能使部分崇拜技术力量的用户因盲从而做出错误的判断。
而Gemini能够以更高的准确度对视频的真实性做出判断,也许恰恰是因为放弃了对技术的迷信,而使用了更为灵活、多元的判断路径,而这样的路径又与事实核查员日常判断视频真伪的思路不谋而合。
我们对Gemini分析思路进行了总结,概括为以下8点,供大家参阅:
1. 评估视频的质量:是否存在画面质量过低或质量参差不齐的情况?
2. 观察关键帧中的细节:画面中的前景与背景是否矛盾?光影是否自然?是否存在文字乱码等常见的AI生成视频的细节?
3. 考察视频的动态连续性:在镜头移动过程中,视频画面中的远景和近景的视角变化(即视差)是否符合物理世界的规律?是否存在“瞬间移动”式的运镜?
4. 音频检测:视频中的声音与视频的内容是否和谐?是否存在音画不同步或声音与说话者口型无法对应的情况?
5. 考虑视频中描述的事件在现实世界中发生的可能性。现实中是否存在视频中展示的技术?在现实生活中能否找到视频中展示的物体?视频展现的场景是否符合现实逻辑?
6. 反搜视频关键帧,确认视频出现的时间,考察当时的社会状况是否与视频展示画面的内容相符。
7. 考虑视频制作的难度:相较于拍摄,使用AI或CGI来表现相同的画面、运镜会更难还是更容易?
8. 搜索外部资料,查看是否有报道或其它视频资料可以佐证被检测视频的内容。
后记
在与Gemini对话的界面上,有个用蓝色星标修饰的“显示思考”的按钮格外显眼。固然,大模型是个黑箱,我们无从探知它的“思考”究竟是一种模仿还是其他。但即便在“奇点时刻”尚未到来之前,这样的“思考”也并非没有意义。
两年半过去,模型的识假辨假的能力有了显著增长,尽管仍然伴随着幻觉。从这个意义上说,人工智能也许并不只是传播风险的放大器,它也有可能成为信息秩序的守门人。无论是检测伪造图像、识别生成视频,还是追溯信息源头,模型的介入或许将使人类拥有更多与虚假信息抗衡的工具。未来,真正的挑战或许不在于让机器像人一样思考,而在于让它帮助人类更清晰地看见现实本身。

